Templates
Most DS projects consist in similar workflows
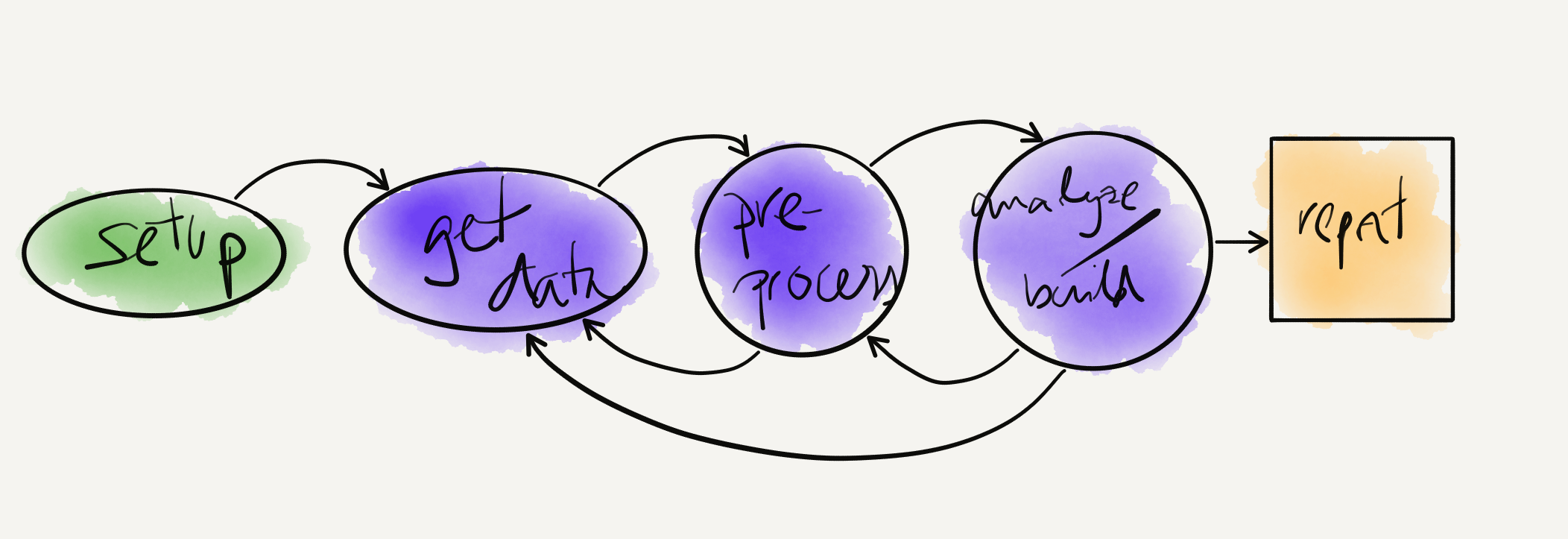
Example one-off data analysis workflow
Most DS projects consist in similar workflows (2)
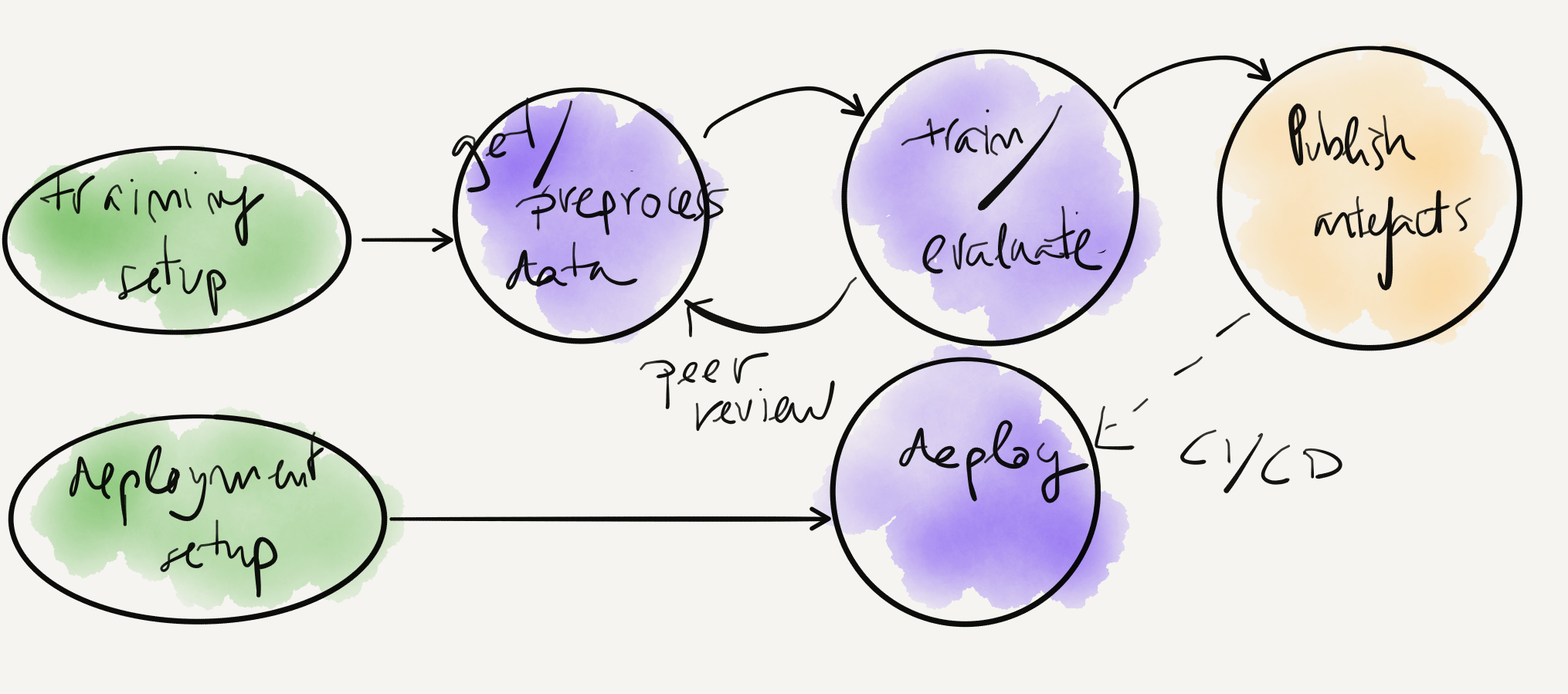
Example train/deploy model workflow
Example project structure
src/
.... package_name/ # package source
........ __init__.py
tests/ # package tests
data/ # input data and artefacts
.... raw/
.... processed/
.... artefacts/
bin/ # scripts
CI/ # CI/CD stuff
setup.py # setuptools for package
environment.yml # environment configuration
Makefile
.gitignore
No one-size-fits-all: Different projects may warrant different structures
Example project structure (2)
- Promotes consistency & good practices
- Facilitates review & reproducibility
- Enables automation
We can use tools like cookiecutter or pyScaffold to create and use templates to reduce cognitive load
cookiecutter Hello world!
# Create a folder with these contents
hello_world_template/
...cookiecutter.json
...{{cookiecutter.directory_name}}/
......hello_world.py
# contents of hello_world.py
print("Hello, {{cookiecutter.your_name}}!")
# contents of cookiecutter.json
{"directory_name": "project_name", "your_name": "Arnau"}
And now, magic:
# to create a new project
cookiecutter hello_world_template
Recommendations
Organize your projects in a clear, consistent, meaningful manner
- Clear: each file and folder are easily understood from their context and name
- Consistent: every project follows the same logic, no surprises
- Meaningful: every choice has a proper motivation
Other opinionated guidelines:
cookiecutter: pre/post hooks
You can automate certain pre/post-project setup tasks with Python or shell scripts:
cookiecutter-something/
├── {{cookiecutter.project_name}}/
├── hooks
│ ├── pre_gen_project.py
│ └── post_gen_project.sh
└── cookiecutter.json
Examples:
- Pre-hook: checking that package name is valid
- Post-hook: initializing git repo
cookiecutter: pre/post hooks (2)
# Example pre_gen_project.py
import re
import sys
PACKAGE_REGEX = r'^[_a-zA-Z][_a-zA-Z0-9]+$'
if not re.match(PACKAGE_REGEX, {{ cookiecutter.package_name }}
sys.exit(1)
# Example pre_gen_project.sh
#!/usr/bin/env bash
echo "Initializing git repository..."
git init
# Commit project skeleton to the repository
git add * # or whatever we want to check-in
git commit -m '{{cookiecutter.module_name}} first commit'
cookiecutter: Jinja Templates
We can use Jinja templates in the cookiecutter.json values:
{
"mod_name": "",
"pkg_name": "{{ cookiecutter.mod_name|lower|replace(' ', '_')|replace('-', '_') }}",
"project_url": "https://github.com/atibaup/{{ cookiecutter.pkg_name }}",
"year": "{% now 'utc', '%Y' %}",
"_extensions": ["jinja2_time.TimeExtension"]
}
Practice time: Build your own template!
Let’s put together the three things we just learned: Set up your own project template with:
1. Your favored project folder structure. You can find inspiration from cookiecutter-data-science, cookiecutter-pypackage, or an example from the 2019 edition.
2. A Makefile with setup, dataset and clean targets, setting up the conda environment and installing the local module (if there is one)
- Pre-cookiecutter hooks to validate the cookiecutter variables
- Post-cookiecutter hooks to initialize a repository
- Bonus: set up pre-commit hooks